Businesses often want to track mentions in the news of themselves, their spokespeople and their competitors, in order to maintain a competitive edge. To support this tracking in media monitoring platforms, sophisticated text analytics components are required. In particular, mentions of the different entities in the article’s text should be automatically identified and linked to their entries in a knowledge base (KB), such as Wikipedia, or Freebase. In fact, this process is called Entity Linking (EL) and can be very challenging as it involves coping with ambiguous names and multiple aliases of the same entity. An example of this process is illustrated in Figure 1.

Figure 1 : example from the Signal-1M dataset
The word ‘Worcester’ in the article’s text is a mention of an entity (a place in this case). EL has two steps: firstly detecting that ‘Worcester’ represents an entity (detection), and secondly linking it to the correct entity in certain KBs (disambiguation). The latter, i.e. disambiguation, involves deciding which Worcester this word is about, as there are many towns around the world which share this particular name (according to Wikipedia, there are more than 10: https://en.wikipedia.org/wiki/Worcester_(disambiguation) ). The correct one in this case is the town in Worcestershire, England, which has a unique identifier in the Wikipedia KB represented by a URL. There are number of open-source EL systems out there that have public APIs and we can use them to perform this task on news articles. An example is Spotlight, which has correctly linked ‘Worcester’ when we feed it with the article’s text.
How do EL systems do that?
Generally, effective EL systems depend heavily on the availability of a sufficient quantity of relevant information about the entities in the KB. Some examples include:
-
The links to wikipedia pages provide a set of possible mentions (aliases for an entity). In our example, the word ‘Worcester’ has been used as the anchor text in those links, and therefore Spotlight has detected that this word represents an entity.
-
The content of the pages representing the entities are useful to learn an appropriate language model that describes them, i.e. the words that they are usually associated with. In our example, we used the context of the mention (the words that appear next to it in the article) for disambiguation: deciding which Worcester in Wikipedia to link it to.
In other words, effective EL systems rely on rich contextual content and metadata describing the entities in their KBs. Such data is not usually rich, yet alone available for all entities out there. Indeed, many off-the-shelf entity linking systems use general KBs such as Freebase and Wikipedia that cover popular entities, e.g. big corporations and celebrities. Many less popular entities or domain-specific entities have a less complete profile or are not covered at all by general KBs, and therefore they cannot be easily linked by these systems.
Long-tail Entities
Recently, we have published a paper in the European Conference in Information Retrieval (ECIR 2017) studying the volume of long-tail entities in the news and the challenges associated to effectively identify and disambiguate them. The term “long-tail entities” describes the large number of entities with relatively few mentions in text collections. They are usually characterised with limited or no general KB profile and sparse or absent resources outside the KB. They are particularly of interest to Signal AI as they represent part of our target audience (small or medium organisations), or their spokespeople. A concrete example of such entities is shown in Figure 1. ‘Worcester’s Breakfast Club for HM Forces and Veterans’ is an example of long-tail entities. It is an organisation which has no profile in Wikipedia. In fact, the Spotlight EL system did not succeed in identifying this entity.
In our paper, we developed an approach to automatically identify long-tail entities, such that we can measure their volume in news corpora. We also uncover insights into the types of entities that cannot be easily linked by off-the-shelf EL systems, which rely on general knowledge bases.
The approach we developed works as follows. We take a large collection of news articles. In this case, we took all the news articles in the Signal-1M dataset, which is collection of 1 million news articles published over a period of 1 month (September 2015) sourced from tens of thousands of news and blog sources. We then fed each article into two different processes:
-
Entity Recognition (ER): this process is similar to the detection step of EL in that it identifies all words and phrases that represent entities along with the type of the entities (whether it is a person, location or organisation). The main difference is that it does not rely on an external KB to do this. Instead, it identifies the mention of the entities and their types using natural language processing and syntactic rules as well as the words that precede or follow them. In particular, we use the Stanford system, which is fairly robust and accurate as shown in previous studies.
-
Entity Linking (EL): the process we described earlier, and in this case we used the off-the-shelf Spotlight system.
Back to our example in Figure 1. We actually show the output of the above two processes on the exemplary article there: bolded phrases/words are the output of the EL process, while underlined is the ER output. Long-tail entities will be typically identified by ER and not by EL. Indeed, Worcester’s Breakfast Club for HM Forces and Veterans’ was identified as an organisation entity by ER, but it was not linked. On the other hand, the popular entity Worcester, with a rich profile in Wikipedia, was picked up by both ER and EL.
Following this, we can use the overlap between the output of these two processes as a proxy to measure the volume of long-tail entities. A low overlap indicates a larger volume of long-tail entities. Note however, when ER identifies an entity mention and EL does not provide the link to the KB, we cannot guarantee that the mention represents an entity in the long-tail as these could be due to the performance of EL, since some entity mentions are so ambiguous.
We repeated this over the million articles in the dataset, and aggregated the results over all the entities identified by ER for different entity types. We show the results in Table 1.
Table 1: Overlap results
| Total Mentions (ER) | No Overlap with EL | |
|---|---|---|
| Person | 7.71 Million | 54.38% |
| Location | 5.52 Million | 7.33% |
| Organisation | 5.37 Million | 14.54% |
The first row in the table is read as follows: in total there are 7.71 million mentions of people’s names in the 1 million news articles identified by the ER process and 54.38% of them (more than 4.1 million people mentions) could not be linked to an entry in the Wikipedia KB by EL. In other words, there is a large number of people mentions in the news that could not be linked at all to general KBs (long-tail entities). From the second and the third row, we can observe that the overlap is lower. However, there is still a large number of organisation mentions (773k) and location mentions (404k) that could not be linked and are likely to represent entities in the long-tail. As a summary of the results, long-tail entities are very common in news and they represent a challenge for EL systems that rely on general KBs.
We conducted another analysis where we looked at how the overlap changes for more popular entity mentions. For this, we order the unique entity mentions by their frequencies, (a total of 2,029,235 are identified by ER) and we estimate the mean no-overlap rate for different subsets of those. In Figure 2, we report the results for two different subsets: the most frequent 0.1% entity mentions (2031 entity mentions) and the most frequent 5%, along with the overall results already reported in Table 1. As expected, we see that the overlap rate decreases but only marginally. In other words, even for very commonly-mentioned entities, the EL is not capable of finding them in Wikipedia.
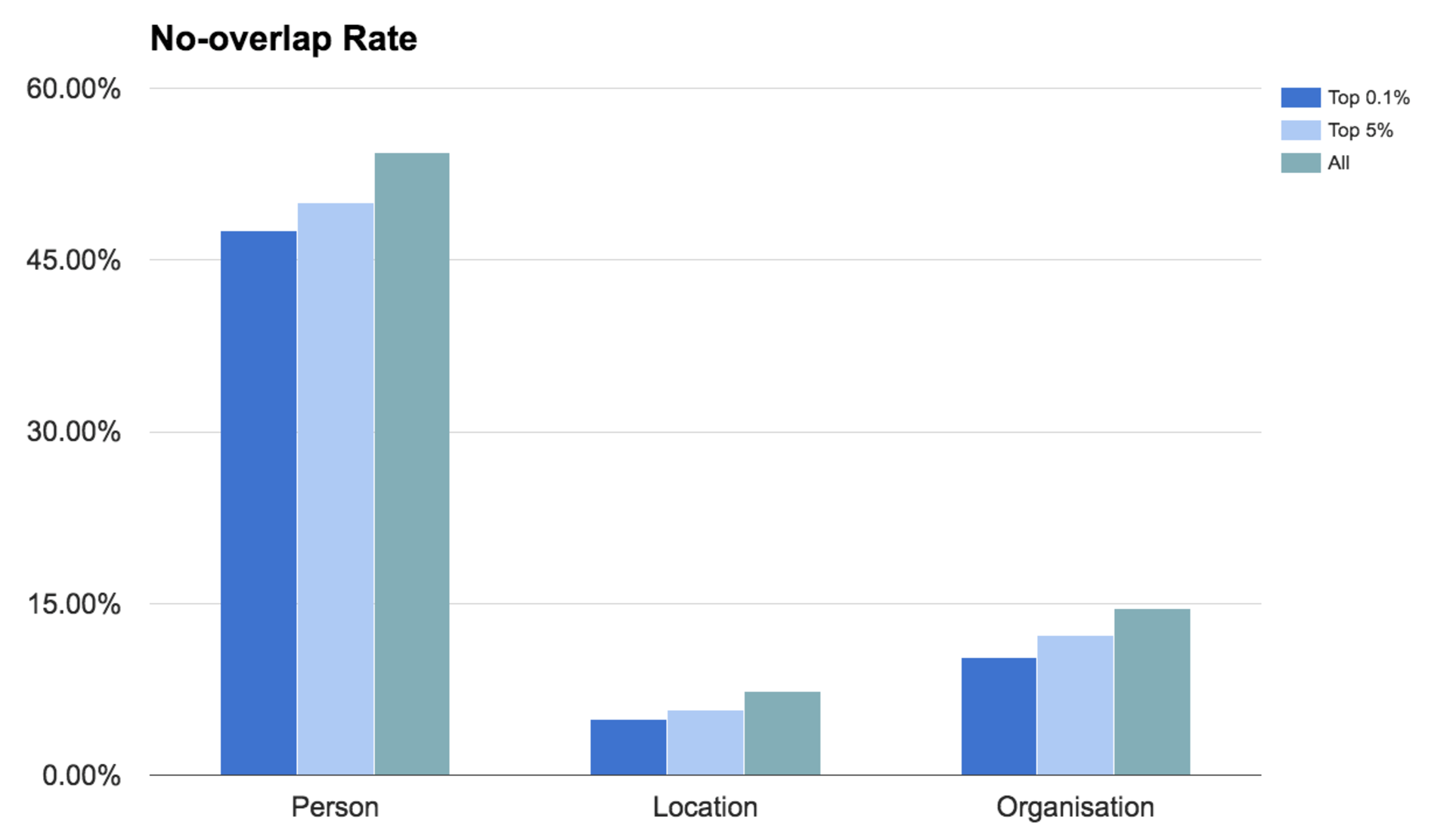
Figure 2: Overlap results for different mention subsets
Recall that a lack of overlap either means that the mention represents a long-tail entity (not covered in the KB) or mistakes by EL due to an entity being very ambiguous. We developed an approach to distinguish between these two cases when a no-overlap occurs. Full details of this is available in the paper, but the main findings were:
-
For highly-frequent entity mentions, we found out that in the majority of the cases, the non-overlap is due to the ambiguity of the entity, i.e. mistakes by the EL system. Examples of such entity mentions are available in Table 2 along with their frequencies in the Signal-1M dataset. As we can see these names represent big organisations with ambiguous names (e.g. ‘jaguars’, the car manufacturer, and ‘nomura’, a Japanese bank), or ambiguous mentions of people e.g. Andy.
-
For less-frequent entity mentions, we found out that in the majority of the cases, the EL fails because the entity is not covered in the KB. Examples are also available in Table 2. In this case, we see mentions of not very popular people or small-medium organisation which are not covered in general KBs.
Table 2: Examples of entity mentions of low overlap with EL output
| High Frequency - EL mistakes | Lower Frequency - Not in Wikipedia | ||
|---|---|---|---|
| mention | frequency | mention | frequency |
| andy | 904 | asigra | 14 |
| jaguars | 1,073 | mark gleeson | 81 |
| nomura | 805 | mique juarez | 12 |
| sedar | 773 | pryce | 10 |
Going Forward
This findings of this study serve as a useful guideline to improve EL systems on news corpora. In particular, we can apply the procedure developed in our paper to automatically identify the above two classes of entity mentions:
-
For highly-frequent but very ambiguous entities, and although they are covered on general KBs, effective EL systems would require more training data for aliases of these entities.
-
For less-frequent entity mentions, one avenue could be considering more specialised knowledge bases such as CrunchBase or AngelList.